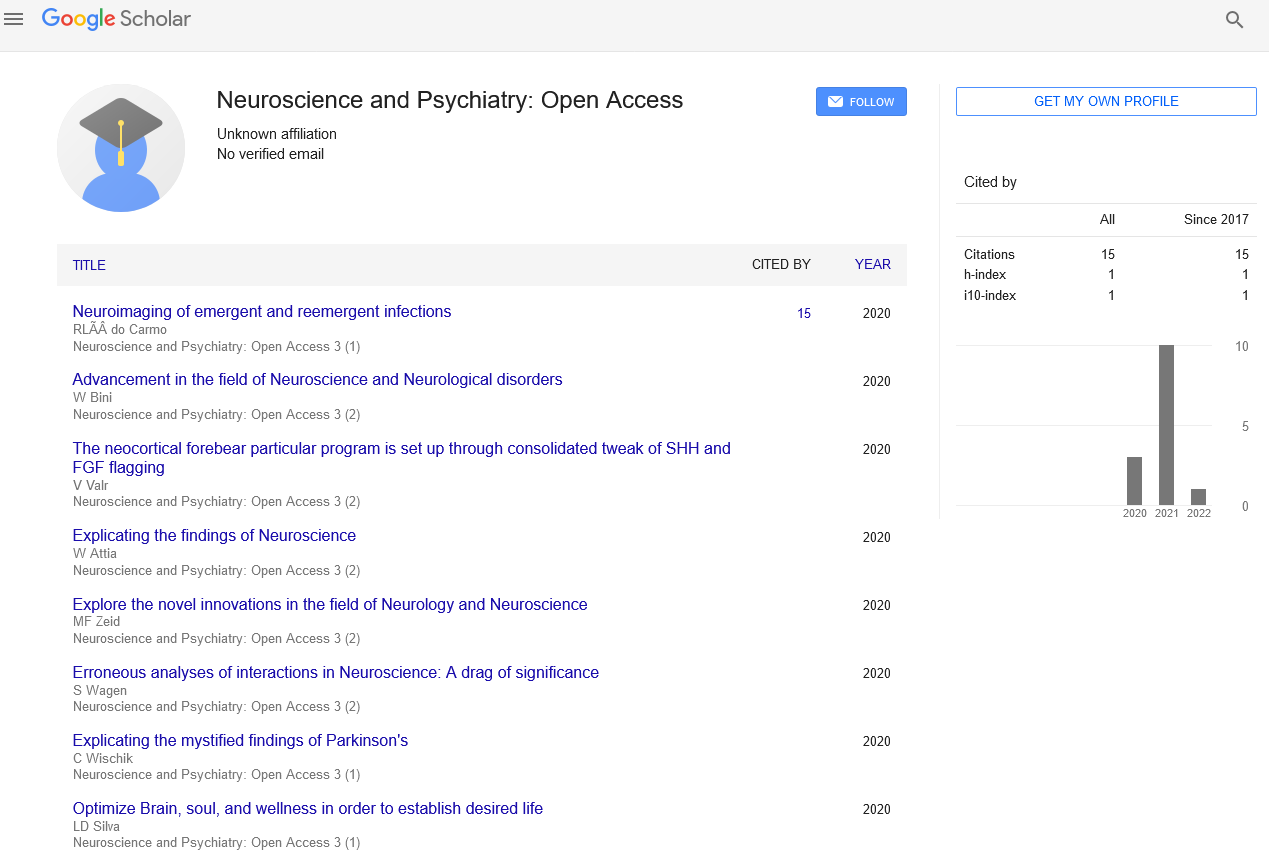
Short Article - Neuroscience and Psychiatry: Open Access (2020) Volume 3, Issue 2
Erroneous analyses of interactions in Neuroscience: A drag of significance
Sander Wagen
Leiden University, The Netherlands
Abstract
In theory, a comparison of 2 experimental effects needs a applied mathematics take a look at on their distinction. In follow, this comparison is usually supported Associate in Nursing incorrect procedure involving 2 separate tests within which researchers conclude that impacts disagree once one effect is important (P < zero.05) however the opposite isn't (P > zero.05). we have a tendency to reviewed 513 activity, systems and neuroscience articles in 5 commanding journals (Science, Nature, Nature neurobiology, vegetative cell and therefore the Journal of Neuroscience) and located that seventy eight used the proper procedure and seventy nine used the wrong procedure. an extra analysis suggests that incorrect analyses of interactions square measure even additional common in cellular and molecular neurobiology. we have a tendency to discuss eventualities within which the inaccurate procedure is especially beguiling. Main “The proportion of neurons showing cue-related activity inflated with coaching within the mutant mice (P < zero.05), however not within the management mice (P > zero.05).” “Animals receiving vehicle (control) infusions into the amygdaloid nucleus showed inflated cooling to the input|stimulation|stimulus|stimulant|input} compared with a sway stimulus (P < zero.01); in animals receiving muscimol infusions into the amygdaloid nucleus, this distinction was abolished (F < 1).”
These 2 fictive, however representative, statements illustrate a applied mathematics error that's common within the neurobiology literature. The researchers World Health Organization created these statements needed to say that one impact (for example, the coaching impact on vegetative cell activity in mutant mice) was larger or smaller than the opposite impact (the coaching impact up to speed mice). To support this claim, they required to report a statistically vital interaction (between quantity of coaching and kind of mice), however instead they reported that one impact was statistically vital, whereas the opposite impact wasn't. though superficially compelling, the latter sort of applied mathematics reasoning is inaccurate as a result of the distinction between vital and not vital needn't itself be statistically significant1. take into account Associate in Nursing extreme situation within which training-induced activity barely reaches significance in mutant mice (for example, P = 0.049) and barely fails to succeed in significance for management mice (for example, P = 0.051). Despite the very fact that these 2 P values lie on opposite
sides of zero.05, one cannot conclude that the coaching impact for mutant mice differs statistically from that for management mice. That is, as splendidly noted by Rosnow and Rosenthal2, “surely, God loves the zero.06 nearly the maximum amount because the zero.05”. Thus, once creating a comparison between 2 effects, researchers ought to report the applied mathematics significance of their distinction instead of the distinction between their significance levels.Our impression was that this error of comparison significance levels is widespread within the neurobiology literature, however so far there have been no combination information to support this impression. we tend to thus examined all of the behavioural, systems and neuroscience studies printed in four prestigious journals (Nature, Science, Nature neurobiology and Neuron) in 2009 and 2010 and in each fourth issue of the 2009 and 2010 volumes of The Journal of neurobiology. In 157 of those 513 articles (31%), the authors describe a minimum of one state of affairs within which they could be tempted to create the error. In five hundredth of those cases ,the authors used the proper approach: they according a major interaction. this could be followed by the report of the easy main effects (that is, separate analyses for the most impact of coaching within the mutant mice and management mice). within the alternative five hundredth of the cases (79 articles), the authors created a minimum of one error of the sort mentioned here: they according no interaction impact, however solely the easy main effects, mentioning the qualitative distinction between their significance values (for example, vehicle infusions were related to a statistically important increase in physical change behavior; muscimol infusions weren't related to a reliable increase in physical change behavior). Table one Outcome of the most literature analysis are of these articles wrong regarding their main conclusions? we tend to don't assume therefore. First, we tend to counted associatey paper containing a minimum of one inaccurate analysis of an interaction. For a given paper, the most conclusions might not rely on the inaccurate analysis. Second, in roughly one third of the error cases, we tend to were convinced that the essential, however missing, interaction impact would are statistically important (consistent with the researchers' claim), either as a result of there was a huge distinction between the 2 impact sizes or as a result of the according method info allowed US to see the approximate significance level. yet, in roughly 2 thirds of the error cases, the error might have had serious consequences. all told of those cases, the nonsignificant distinction, though smaller in size, was within the same direction because the important distinction. additionally, the method info failed to permit US to see the importance level of the missing interaction check. we've got no manner of assessing the severity of those cases. Most of the errors might not have severe implications. In some cases,however, the error might contribute well to the article's main conclusions. Because of our background experience, our main analysis centered on behavioural, systems and neuroscience. However, it's possible that the wrong analysis of interactions isn't simply restricted to those disciplines. to substantiate this intuition, we tend to reviewed a further a hundred and twenty cellular and molecular neurobiology articles printed in Nature neurobiology in 2009 and 2010 (the 1st 5 Articles in every issue). we tend to failed to realize one study that used the proper method to match impact sizes. In distinction, we tend to found a minimum of twenty five studies that used the inaccurate procedure and expressly or implicitly compared significance levels. In general, information collected in these cellular and molecular neurobiology studies were analyzed principally with t tests (possibly corrected for multiple comparisons or unequal variances) and infrequently with unidirectional ANOVAs, even once the experimental style was complex and needed a a lot of refined applied math analysis. Our literature analyses showed that the error happens in many alternative situations: once researchers compared the results of a medical specialty agent versus placebo; patients versus controls; one versus another task condition, brain space or time point; genetically changed versus wild-type animals; younger versus older participants; etc. we tend to describe 3 general kinds of things within which the error happens and illustrate every with a archetypical (fictive) example. First, most of the errors that we tend to encountered in our associatealysis occurred once comparison impact sizes in an experimental group/condition and a bearing group/condition (for example, sham-TMS, vehicle infusion, placebo pill, wild-type mice). the 2 examples at the beginning of this text belong to the present sort. The researchers distinction the importance levels of the 2 impact sizes rather than news the importance level of a right away applied math comparison between the impact sizes. The claim that the impact of the optogenetic manipulation on P3 amplitude is larger within the virally transduced animals than within the management animals needs a major interaction between the manipulation (photoinhibition versus baseline) and cluster (virally transduced versus management mice). as a result of the aforethought results replicate the cluster averages of individual averages that 10dency to|we tend to} generated ourselves (for ten mice in every group), we all know that the interaction during this example isn't important (P > zero.05). Thus, the claim that the researchers shall build isn't statistically valid. Figure 1: Graphs illustrating the assorted kinds of things within which the error of comparison significance levels happens.(a) comparison impact sizes in associate experimental group/condition and a bearing group/condition. (b) comparison impact sizes throughout a pre-test and a post- test. (c) comparison many brain areas and claiming that a specific impact (property) is restricted for one among thesebrain areas. (d) information conferred during a, when taking the distinction of the 2 repeated-measures (photoinhibition and baseline). Error bars indicate s.e.m.; ns, nonsignificant (P > zero.05), *P < 0.05, **P < 0.01. Second, comparison impact sizes throughout a pre-test and a post-test will be seen as a special case of things delineate higher than, within which the pre-test (before the experimental manipulation) is that the criterion and also the post-test (after the manipulation) is that the process. associate example is
“Acute SSRI treatment exaggerated social approach behavior (as indexed by sniff time) in our mouse model of depression (P < zero.01)” (Fig. 1b). Errors of this sort square measure less common and infrequently less express. during this example, the researchers distinction solely the posttest many the 2 teams, on the silent assumption that they have not take under consideration the corresponding pre-test scores, maybe as a result of the pre-test scores don't faithfully dissent between teams. Thus, the researchers implicitly base their claim on the distinction between the many post-test distinction and also the nonsignificant pre- test distinction, once instead they ought to have directly compared the impact sizes, for instance, by examining the time × cluster interaction during a repeatedmeasures analysis of variance.
The third form of error happens once comparison many brain areas and claiming that a specific impact (property) is restricted for one among these brain areas. during this form of state of affairs, researchers don't compare a chosen region of interest with a bearing space, however instead compare variety of brain areas with a lot of or less equal 'a priori That is, at the terribly least, abstraction memory ought to be a lot of impaired in animals with enthorinal lesions than in animals with lesions in alternative areas.Thus, the specificity claim needs that the researchers report a major time × lesion sort interaction, followed by important pair-wise comparisons between the precise brain space and also the alternative brain areas. These 3 examples involve errors that we might classify as being probably serious, because the nonsignificant impact is within the same direction because the important impact (except for the chemoreceptor cortex), and since the knowledge in Figure 1a–c isn't adequate to estimate the importance of the missing interaction check. the explanation is that every of those 3 graphs contains continual measurements (for example, before and when treatment). within the case of continual measurements on constant group(s) of subjects, the standard-error bars don't provide the knowledge required to assess the importance of the variations between the continual measurements, as they're not sensitive to the correlations between these measurements3. Standard-error bars will solely be accustomed assess the importance of between-group variations. Thus, the reader will solely decide whether or not associate interaction would be important if the suggests that and commonplace errorsreplicate the distinction between continual measurements (as in Fig. 1d, that is predicated on constant information as Fig. 1a). Thus, not like Figure 1a, we are able to use Figure 1d to estimate the importance of the interaction by comparison the scale of the gap (or in alternative things the degree of overlap) between the 2 error bars4. We have mentioned errors that occur once researchers compare experimental effects. However, in our analysis, we tend to found that the error additionally happens once researchers compare correlations. once creating a comparison between 2 correlations, researchers ought to directly distinction the 2 correlations exploitation associate acceptable statistical procedure. As noted by others5,6, the error of comparison significance levels is very common within the neuroimaging literature, within which results square measure generally conferred in color-coded applied math maps indicating the importance level of a specific distinction for every (visible) voxel. a visible comparison between maps for 2 teams would possibly tempt the investigator to state. Similarly, claims regarding variations in activation across brain regions should be supported by a major interaction between brain region and also the issue underlying the distinction of interest. Identification of the many response within the insular cortex doesn't imply that this region is unambiguously or a lot of powerfully concerned in creating ethical judgments than alternative regions. It simply implies that, though the null hypothesis has been rejected during this region, it's not been rejected elsewhere.
It is fascinating that this applied math error happens therefore typically, even in journals of the best commonplace. area constraints and also the want for simplicity could also be the explanations why the error happens in journals like Nature and Science. news interactions in associate analysis of variance style could seem to a fault complicated once one is writing for a general audience. Perhaps, in some cases, researchers favor to report the distinction between significance levels as a result of the corresponding interaction impact isn't important. Peer reviewers ought to facilitate authors avoid such mistakes.
The applied math error can also be a manifestation of the formation effect7, the development that a lot of people's confidence during a result drops short once a P price will increase simply on the far side the zero.05 level. Indeed, individuals square measure typically tempted to attribute an excessive amount of intending to the distinction between important and not important. For this reason, the employment of confidence intervals might facilitate stop researchers from creating this applied math error. regardless of the reasons for the error, its omnipresence and potential impact recommend that researchers and reviewers ought to be a lot of aware that the distinction between important and not important isn't itself essentially important.